Maschinelles Dichten: Unterschied zwischen den Versionen
Aus exmediawiki
C.heck (Diskussion | Beiträge) |
C.heck (Diskussion | Beiträge) Keine Bearbeitungszusammenfassung |
||
| (10 dazwischenliegende Versionen desselben Benutzers werden nicht angezeigt) | |||
| Zeile 1: | Zeile 1: | ||
[[AI@exLabIII|Seminar]], '''31.10.2019''' | |||
=KHM-Wolke= | =KHM-Wolke= | ||
Anleitung: [[KHM-Wolke einrichten]] | Anleitung: [[KHM-Wolke einrichten]] | ||
| Zeile 22: | Zeile 23: | ||
* was richtete eure aufmerksamkeit in den letzten tagen/wochen/monaten besonders auf sich? d.h. welche debatten, news, diskussionen mit euren freunden/bekannten in diesem kontext? | * was richtete eure aufmerksamkeit in den letzten tagen/wochen/monaten besonders auf sich? d.h. welche debatten, news, diskussionen mit euren freunden/bekannten in diesem kontext? | ||
* wie lautet deine künstlerische Fragestellung? | * wie lautet deine künstlerische Fragestellung? | ||
<!-- | |||
---- | ---- | ||
human@machine $ whoami | human@machine $ whoami | ||
| Zeile 39: | Zeile 41: | ||
* Oktober 2018: https://www.heise.de/newsticker/meldung/Amazon-KI-zur-Bewerbungspruefung-benachteiligte-Frauen-4189356.html | * Oktober 2018: https://www.heise.de/newsticker/meldung/Amazon-KI-zur-Bewerbungspruefung-benachteiligte-Frauen-4189356.html | ||
** Amazon: KI zur Bewerbungsprüfung benachteiligte Frauen - Ein automatisches Bewertungssystem von Bewerbungen bei Amazon wurde größtenteils eingestampft, nachdem der US-Konzern mitbekommen hatte, dass die KI Frauen systematisch benachteiligte. Das geht aus einem [https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G Bericht der Nachrichtenagentur Reuters] hervor. Demnach war seit 2014 intern ein Algorithmus entwickelt worden, der unter mehreren Bewerbungstexten automatisch jene der vielversprechendsten Bewerber herausfiltern sollte. | ** Amazon: KI zur Bewerbungsprüfung benachteiligte Frauen - Ein automatisches Bewertungssystem von Bewerbungen bei Amazon wurde größtenteils eingestampft, nachdem der US-Konzern mitbekommen hatte, dass die KI Frauen systematisch benachteiligte. Das geht aus einem [https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G Bericht der Nachrichtenagentur Reuters] hervor. Demnach war seit 2014 intern ein Algorithmus entwickelt worden, der unter mehreren Bewerbungstexten automatisch jene der vielversprechendsten Bewerber herausfiltern sollte. | ||
--> | |||
---- | ---- | ||
| Zeile 167: | Zeile 169: | ||
---- | ---- | ||
= | =Stimmungsanalyse= | ||
[[Datei:Textblob.jpeg|500px]] | |||
in short: | |||
Opinion Mining (manchmal als Stimmungsanalyse oder Emotion AI ) bezieht sich auf | |||
* die Verwendung von natürlicher Sprachverarbeitung, Textanalyse , Computerlinguistik und Biometrie, | |||
* systematisches Identifizieren, Extrahieren, Quantifizieren und studieren affektiver Zustände, sowie subjektiver Informationen. | |||
Generell zielt Sentimentanalyse darauf ab, die Haltung eines Sprechers/Autors in Bezug auf einige Themen oder die kontextuelle Polarität / emotionale Reaktion auf ein Dokument, eine Interaktion, oder ein Ereignis zu bestimmen. | |||
---- | ---- | ||
Wikipedia: | |||
Sentiment Detection (auch Sentimentanalyse, englisch für „Stimmungserkennung“) ist ein Untergebiet des Text Mining und bezeichnet die automatische Auswertung von Texten mit dem Ziel, eine geäußerte Haltung als positiv oder negativ zu erkennen. | Sentiment Detection (auch Sentimentanalyse, englisch für „Stimmungserkennung“) ist ein Untergebiet des Text Mining und bezeichnet die automatische Auswertung von Texten mit dem Ziel, eine geäußerte Haltung als positiv oder negativ zu erkennen. | ||
* see: https://de.wikipedia.org/wiki/Sentiment_Detection#Einf%C3%BChrung | * see: https://de.wikipedia.org/wiki/Sentiment_Detection#Einf%C3%BChrung | ||
==textblob== | ==textblob== | ||
TextBlob ist ein Tool für natural language processing (NLP) mit Python. | TextBlob ist ein Tool für natural language processing (NLP) mit Python. | ||
| Zeile 195: | Zeile 191: | ||
===textblob in short=== | ===textblob in short=== | ||
type in terminal: | |||
pip install textblob | pip install textblob | ||
type in Notebook: | |||
from textblob import TextBlob | from textblob import TextBlob | ||
textsnippet = TextBlob('not a very great experiment') | textsnippet = TextBlob('not a very great experiment') | ||
print(textsnippet.sentiment) | print(textsnippet.sentiment) | ||
---- | ---- | ||
[[Category:Seminar]] | |||
[[ | [[Category:KI]] | ||
[[Category: Natural Language Processing]] | |||
[[Category:AI Poetry]] | |||
[[Category:Python]] | |||
[[Category:Sentiment Analysis]] | |||
[[Category:WS2019-20]] | |||
Aktuelle Version vom 31. Mai 2020, 15:02 Uhr
Seminar, 31.10.2019
KHM-Wolke
Anleitung: KHM-Wolke einrichten
was bietet euch diese Cloud?:
- Filesharing zwischen eigenen und den Lab-Rechnern
- Eigene Cloud
- Eigener Kalender, Passwortcontainer, Mindmaps etc.
- Frontend für euren E-Mail Account
--
Vorstellungsrunde
human@machine $ whoareyou
Frage1 an euch:
- was richtete eure aufmerksamkeit in den letzten tagen/wochen/monaten besonders auf sich? d.h. welche debatten, news, diskussionen mit euren freunden/bekannten in diesem kontext?
- wie lautet deine künstlerische Fragestellung?
Exkursion/Gäste in diesem Semester
-
 Thomas Wagner 07.11.2019 AI@exLabIII#Thomas_Wagner
Thomas Wagner 07.11.2019 AI@exLabIII#Thomas_Wagner -
 capulcu 14.11.2019 AI@exLabIII#capulcu
capulcu 14.11.2019 AI@exLabIII#capulcu -
 Christoph Marischika 05.12.2019 AI@exLabIII#Krieg & KI
Christoph Marischika 05.12.2019 AI@exLabIII#Krieg & KI -
 Fiffkon 22.-24.11. AI@exLabIII#Exkursion
Fiffkon 22.-24.11. AI@exLabIII#Exkursion -
 Workshop und Diskussion mit Matthias Burba und Klaus Fritze in DNA phenotyping, Freitags @ Open Lab
Workshop und Diskussion mit Matthias Burba und Klaus Fritze in DNA phenotyping, Freitags @ Open Lab





Projektpräsentation - Verena Lercher
Verena Lercher stellt ihre künstlerische Arbeit vor:
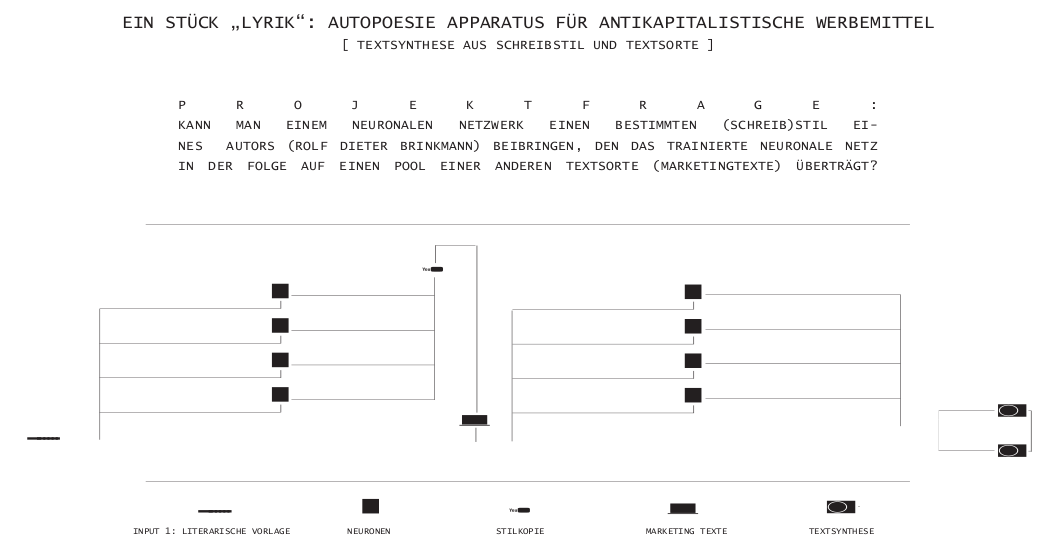
Ross Goodwin on the Road
Not a poet.
Ross Goodwin is an Artist, creative technologist, hacker, gonzo data scientist, writer of writers. Graduate of NYU ITP & MIT; former Obama administration ghostwriter. Employs machine learning, natural language processing, other computational tools to realize new forms & interfaces for written language.
wordcar https://github.com/rossgoodwin/wordcar
Artikel:
- https://medium.com/artists-and-machine-intelligence/ai-poetry-hits-the-road-eb685dfc1544
- https://bombmagazine.org/articles/ross-goodwins-1-the-road/
- https://fm4.orf.at/stories/2874687/
Jupyter Notebooks Einführung
Offizielle Dokumentation: https://jupyter-notebook.readthedocs.io/en/stable/index.html
Jupyter ist eine Webapplikation, die das Arbeiten mit sogenannten Jupyter Notebooks ermöglicht. In Jupyter Notebooks kann man neben Code (nicht nur Python) auch formatierten Text, Links, Bilder, Videos und interaktive Widgets generieren, laufen lassen und exportieren. Neben der modernen Jupyter-Umgebung kann man Python auch im klassichen Interface “Editor + Command Line” verwenden.
Markdown Syntax
Markdown hat Ähnlichkeiten mit einer Computersprache, ist aber wesentlich einfacher konzipiert und soll so für jeden verständlich sein. Markdown ermöglicht es, Texte im Web zu formatieren, ohne das betreffende Dokument dazu mit eckigen Klammern, Befehlen und sonstigen Kommandos zu überfluten, wie man sie für ein gestyltes HTML-Dokument normalerweise benötigt.
Am besten zeigen sich die Vorteile von Markdown in einem Praxisbeispiel. Zwei Absätze mit Text und einer Überschrift sollen gestylt werden – der erste kursiv, und der Zweite gefettet. In klassischem HTML müsste man eigentlich folgenden Code verfassen:
<h2>Markdown-Test</h2>
<p><strong>Dieser Text soll fett geschrieben werden.</strong></p>
<p><em>Und dieser Absatz soll kursiv angezeigt werden.</em></p>
In Markdown würde das obere Beispiel wie folgt aussehen:
## Markdown-Test **Dieser Text soll fett geschrieben werden.** *Und dieser Absatz soll kursiv angezeigt werden.*
- zum Ausprobieren, siehe Notebook in Cloud: Markdown-basics.ipynb
Markdown hilfe:
advanced:
erste Schritte mit Python
Variablen setzen
var_string = "null" var_int = 0
Ausgaben mit print()
print(var_int)
print("Hallo Welt")
Eingaben mit input()
Text:
input("Schreibe ein Wort:")
Ganzzahl:
int(input("Schreibe eine Ganzzahl:"))
Fließkommazahl:
float(input("Schreibe eine Fließkommazahl:"))
die »for«-Schleife
liste = ["Alles", "macht", "weiter"]
for i in liste:
print(i)
Kommentare
Einzeiliges Kommentar
# mit dem Hashtag zu Beginn einer Zeile wird auskommentiert
mehrzeilige Kommentare:
"""In 3 Anführungszeichen können mehrzeilige Kommentare (__doc__strings) verfasst werden"""
Python Tutorials
Onlinetutorial:
Book:
Videotutorial:
Hands-on Tutroial:
Stimmungsanalyse

in short:
Opinion Mining (manchmal als Stimmungsanalyse oder Emotion AI ) bezieht sich auf
- die Verwendung von natürlicher Sprachverarbeitung, Textanalyse , Computerlinguistik und Biometrie,
- systematisches Identifizieren, Extrahieren, Quantifizieren und studieren affektiver Zustände, sowie subjektiver Informationen.
Generell zielt Sentimentanalyse darauf ab, die Haltung eines Sprechers/Autors in Bezug auf einige Themen oder die kontextuelle Polarität / emotionale Reaktion auf ein Dokument, eine Interaktion, oder ein Ereignis zu bestimmen.
Wikipedia:
Sentiment Detection (auch Sentimentanalyse, englisch für „Stimmungserkennung“) ist ein Untergebiet des Text Mining und bezeichnet die automatische Auswertung von Texten mit dem Ziel, eine geäußerte Haltung als positiv oder negativ zu erkennen.
textblob
TextBlob ist ein Tool für natural language processing (NLP) mit Python.
Mit Textblob sind viele Ansätze wie etwa Erkennen von Wortarten, Extraktion von Substantiven, Stimmungsanalyse und auch Klassifizierungen möglich.
textblob in short
type in terminal:
pip install textblob
type in Notebook:
from textblob import TextBlob
textsnippet = TextBlob('not a very great experiment')
print(textsnippet.sentiment)