Maschinelles Dichten
Aus exmediawiki
31.10.2019
KHM-Wolke
Anleitung: KHM-Wolke einrichten
was bietet euch diese Cloud?:
- Filesharing zwischen eigenen und den Lab-Rechnern
- Eigene Cloud
- Eigener Kalender, Passwortcontainer, Mindmaps etc.
- Frontend für euren E-Mail Account
--
Vorstellungsrunde
human@machine $ whoareyou
Frage1 an euch:
- was richtete eure aufmerksamkeit in den letzten tagen/wochen/monaten besonders auf sich? d.h. welche debatten, news, diskussionen mit euren freunden/bekannten in diesem kontext?
- wie lautet deine künstlerische Fragestellung?
Exkursion/Gäste in diesem Semester
-
 Thomas Wagner 07.11.2019 AI@exLabIII#Thomas_Wagner
Thomas Wagner 07.11.2019 AI@exLabIII#Thomas_Wagner -
 capulcu 14.11.2019 AI@exLabIII#capulcu
capulcu 14.11.2019 AI@exLabIII#capulcu -
 Christoph Marischika 05.12.2019 AI@exLabIII#Krieg & KI
Christoph Marischika 05.12.2019 AI@exLabIII#Krieg & KI -
 Fiffkon 22.-24.11. AI@exLabIII#Exkursion
Fiffkon 22.-24.11. AI@exLabIII#Exkursion -
 Workshop und Diskussion mit Matthias Burba und Klaus Fritze in DNA phenotyping, Freitags @ Open Lab
Workshop und Diskussion mit Matthias Burba und Klaus Fritze in DNA phenotyping, Freitags @ Open Lab





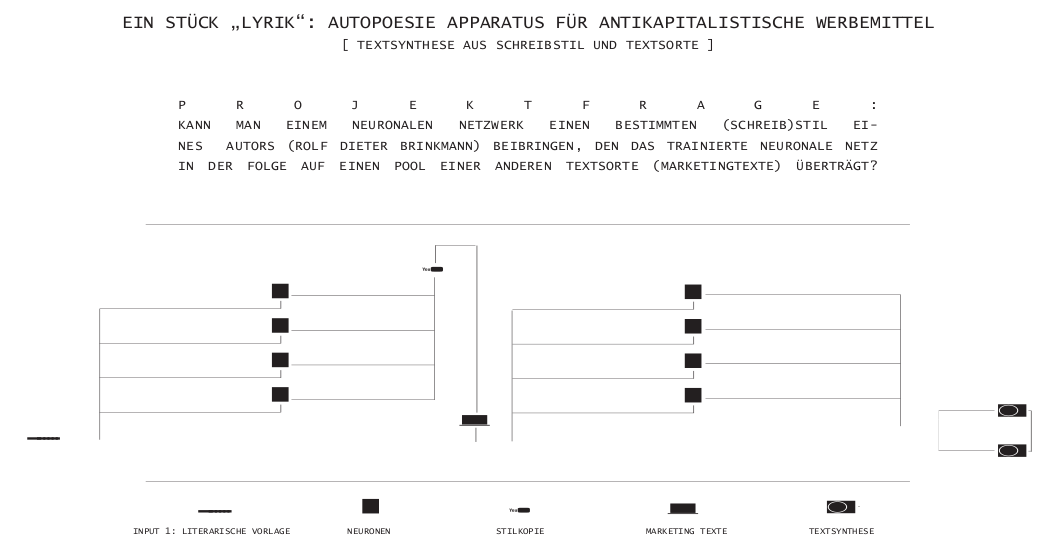
Projektpräsentation - Verena Lercher
Verena Lercher stellt ihre künstlerische Arbeit vor:
Ross Goodwin on the Road
Not a poet.
Ross Goodwin is an Artist, creative technologist, hacker, gonzo data scientist, writer of writers. Graduate of NYU ITP & MIT; former Obama administration ghostwriter. Employs machine learning, natural language processing, other computational tools to realize new forms & interfaces for written language.
wordcar https://github.com/rossgoodwin/wordcar
Artikel:
- https://medium.com/artists-and-machine-intelligence/ai-poetry-hits-the-road-eb685dfc1544
- https://bombmagazine.org/articles/ross-goodwins-1-the-road/
- https://fm4.orf.at/stories/2874687/
Jupyter Notebooks Einführung
Offizielle Dokumentation: https://jupyter-notebook.readthedocs.io/en/stable/index.html
Jupyter ist eine Webapplikation, die das Arbeiten mit sogenannten Jupyter Notebooks ermöglicht. In Jupyter Notebooks kann man neben Code (nicht nur Python) auch formatierten Text, Links, Bilder, Videos und interaktive Widgets generieren, laufen lassen und exportieren. Neben der modernen Jupyter-Umgebung kann man Python auch im klassichen Interface “Editor + Command Line” verwenden.
Markdown Syntax
Markdown hat Ähnlichkeiten mit einer Computersprache, ist aber wesentlich einfacher konzipiert und soll so für jeden verständlich sein. Markdown ermöglicht es, Texte im Web zu formatieren, ohne das betreffende Dokument dazu mit eckigen Klammern, Befehlen und sonstigen Kommandos zu überfluten, wie man sie für ein gestyltes HTML-Dokument normalerweise benötigt.
Am besten zeigen sich die Vorteile von Markdown in einem Praxisbeispiel. Zwei Absätze mit Text und einer Überschrift sollen gestylt werden – der erste kursiv, und der Zweite gefettet. In klassischem HTML müsste man eigentlich folgenden Code verfassen:
<h2>Markdown-Test</h2>
<p><strong>Dieser Text soll fett geschrieben werden.</strong></p>
<p><em>Und dieser Absatz soll kursiv angezeigt werden.</em></p>
In Markdown würde das obere Beispiel wie folgt aussehen:
## Markdown-Test **Dieser Text soll fett geschrieben werden.** *Und dieser Absatz soll kursiv angezeigt werden.*
- zum Ausprobieren, siehe Notebook in Cloud: Markdown-basics.ipynb
Markdown hilfe:
advanced:
erste Schritte mit Python
Variablen setzen
var_string = "null" var_int = 0
Ausgaben mit print()
print(var_int)
print("Hallo Welt")
Eingaben mit input()
Text:
input("Schreibe ein Wort:")
Ganzzahl:
int(input("Schreibe eine Ganzzahl:"))
Fließkommazahl:
float(input("Schreibe eine Fließkommazahl:"))
die »for«-Schleife
liste = ["Alles", "macht", "weiter"]
for i in liste:
print(i)
Kommentare
Einzeiliges Kommentar
# mit dem Hashtag zu Beginn einer Zeile wird auskommentiert
mehrzeilige Kommentare:
"""In 3 Anführungszeichen können mehrzeilige Kommentare (__doc__strings) verfasst werden"""
Python Tutorials
Onlinetutorial:
Book:
Videotutorial:
Hands-on Tutroial:
Module nachinstallieren
das Natural Language Toolkit NLTK zu installieren
open conda and type:
conda install nltk
textblob-de installieren
Die Installation von textblob-de erfolgt in zwei Schritten.
1.Terminal start & type:
pip install -U textblob-de
„-U“ sorgt dafür, dass alle notwendigen Abhängigkeiten auf die neueste Version gebracht werden.
2. Sprachmodelle und Sprachdaten aus dem Natural Language Toolkit (NLTK) hinzufügen:
python3 -m textblob.download_corpora
Stimmungsanalyse

in short:
Opinion Mining (manchmal als Stimmungsanalyse oder Emotion AI ) bezieht sich auf
- die Verwendung von natürlicher Sprachverarbeitung, Textanalyse , Computerlinguistik und Biometrie,
- systematisches Identifizieren, Extrahieren, Quantifizieren und studieren affektiver Zustände, sowie subjektiver Informationen.
Generell zielt Sentimentanalyse darauf ab, die Haltung eines Sprechers/Autors in Bezug auf einige Themen oder die kontextuelle Polarität / emotionale Reaktion auf ein Dokument, eine Interaktion, oder ein Ereignis zu bestimmen.
Wikipedia:
Sentiment Detection (auch Sentimentanalyse, englisch für „Stimmungserkennung“) ist ein Untergebiet des Text Mining und bezeichnet die automatische Auswertung von Texten mit dem Ziel, eine geäußerte Haltung als positiv oder negativ zu erkennen.
textblob
TextBlob ist ein Tool für natural language processing (NLP) mit Python.
Mit Textblob sind viele Ansätze wie etwa Erkennen von Wortarten, Extraktion von Substantiven, Stimmungsanalyse und auch Klassifizierungen möglich.
textblob in short
type in terminal:
pip install textblob
type in Notebook:
from textblob import TextBlob
textsnippet = TextBlob('not a very great experiment')
print(textsnippet.sentiment)
Vorverarbeitung von Texten

see also: https://machinelearningmastery.com/clean-text-machine-learning-python/
Wir benutzen hierzu
- die gängigen Python-Tools
- NltK, das Natural Language Toolkit
- textblob-de
Tokenization
type @lindner lol, that was #awesome :) in: https://text-processing.com/demo/tokenize/
Whitespace Tokenizer in Python
Mit der Python-Funktion Split() können wir einen Text leicht aufteilen. In vielen Fällen machen wir dann aber Fehler. Es fängst schon damit an, dass Satzzeichen am vorangehende Wort geschrieben werden, aber nicht dazu gehören, es sei denn, das Wort ist eine Abkürzung oder eine Ordinalzahl, aber letzteres nur im Deutschen...
splitten mit python (whitespace):
token_WS=gedicht1.split() print(token_WS)
Treebank Tokenizer mit NLTK
Im nächsten Beispiel sehen wir, wie man mit Python und NLTK eine Zeichenkette in eine Liste von Wörtern aufteilen kann. Wir finden nicht nur Wörter, sondern auch Satzzeichen, Zahlen und Symbole. Der Sammelbegriff für diese Einheiten ist Token. Das Zerlegen einer Zeichenkette in Tokens wird daher Tokenisierung oder auf Engslisch Tokenization genannt.
#from nltk.tokenize import TreebankWordTokenizer from nltk import word_tokenize
---
# satz by word separieren tokened_W=word_tokenize(gedicht1, language='german') print(tokened_W)
---
tweet = "@lindner lol, that was #awesome :)" tokened_tweet=word_tokenize(tweet, language='english') print(tokened_tweet)
oder mit textblob-de...
from textblob_de import Word from textblob_de import TextBlobDE as TextBlob
---
tokened_blob_W=TextBlob(gedicht1) print(tokened_blob_W) print(tokened_blob_W.words)
Stemming & Lemmatization
In vielen Sprachen, wie auch im Deutschen und Englischen, können Wöter in verschiedenen Formen auftreten. (Es gibt auch Sprachen, in denen das nicht der Fall ist. Diese Sprachen werden isolierende Sprachen genannt. Beispiele hierfür sind Mandarin (Chinesisch) und Vietnamesisch)). Oft ist es wichtig, den Grundfom eines Wortes, das im Text in flektierter Form vorkommt, zu bestimmen. Es ist wichtig, dass wir hie drei Begriffe klar trennen:
- Lemma - Die Form des Wortes, wie sie in einem Wörterbuch steht. Z.B.: Haus, laufen, begründen
- Stamm - Das Wort ohne Flexionsendungen (Prefixe und Suiffixe). Z.B.: Haus, lauf, begründ
- Wurzel - Kern des Wortes, von dem das Wort ggf. durch Derivation abgeleitet wurde. Z.B.: Haus, lauf, Grund
Wir unterscheiden jetzt Stemmer, Programme, die den Stamm eines Wortes suchen, und Lemmatisierer, die das Lemma für jedes Wort suchen.
https://text-processing.com/demo/stem/
tokened_blob_W.words.lemmatize()